
Introduction
Object detection is the task defined as the combination of:
- Object Localization is the method of locating an object in the image using a bounding box
- Object Classification is the method that tells what is in that bounding box.
What is YOLO
You Only Look Once (YOLO): Unified, Real-Time Object Detection is a single-stage object detection model published at CVPR 2016, by Joseph Redmon, famous for having low latency and high accuracy.
YOLO (You Only Look Once) is a family of object detection models that frames detection as a single regression problem. Single stage because it looks at the entire image and tries to identify all objects at once without relying to multiple stages such as region proposal followed by classification
What is SSD
SSD(Single Shot Detector) was presented in This paper to detects objects using multiple layers of the convolutional network.
Like YOLO, it performs classification and localization in a single stage. However, SSD differs by using multiple feature maps at different scales within the network to detect objects of various sizes, which can improve performance on small or overlapping objects.
Understanding YOLO
YOLO takes a larger input image (e.g., 448×448) and passes it through a custom convolutional network followed by fully connected layers. The network divides the image into a grid (commonly 7×7), and each grid cell is responsible for predicting bounding boxes and class probabilities. Unlike SSD, which detects objects from multiple layers, YOLO makes all predictions from a single output layer,resulting in fewer total predictions.
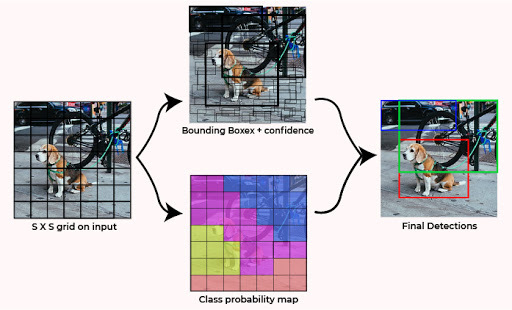
YOLO algorithm works in three steps: residual block or gridding, bounding-box regression, and IoU.
- The first step is dividing the original image into a S*S grid cells.
- Localization regression / Bounding box regression
- Each cell is responsible for localizing and predicting the class of the object it covers with the confidence value. If the centre of the bounding box of the object is in that grid.
- Each grid predicts bounding boxes with their confidence score.
- Each confidence score shows how accurate it is that the bounding box predicted contains an object and how precise it predicts the bounding box coordinates with respect to ground truth prediction.
- It also uses Intersection over Union (IoU) methodology to determine multiple objects of the same class in a single image. Setting a threshold for the IOU is not always enough because an object can have multiple boxes with IOU beyond the threshold, and leaving all those boxes might include noise. Here is where we can use Non-Max Suppression or NMS to keep only the boxes with the highest probability detection score.
Understanding SSD
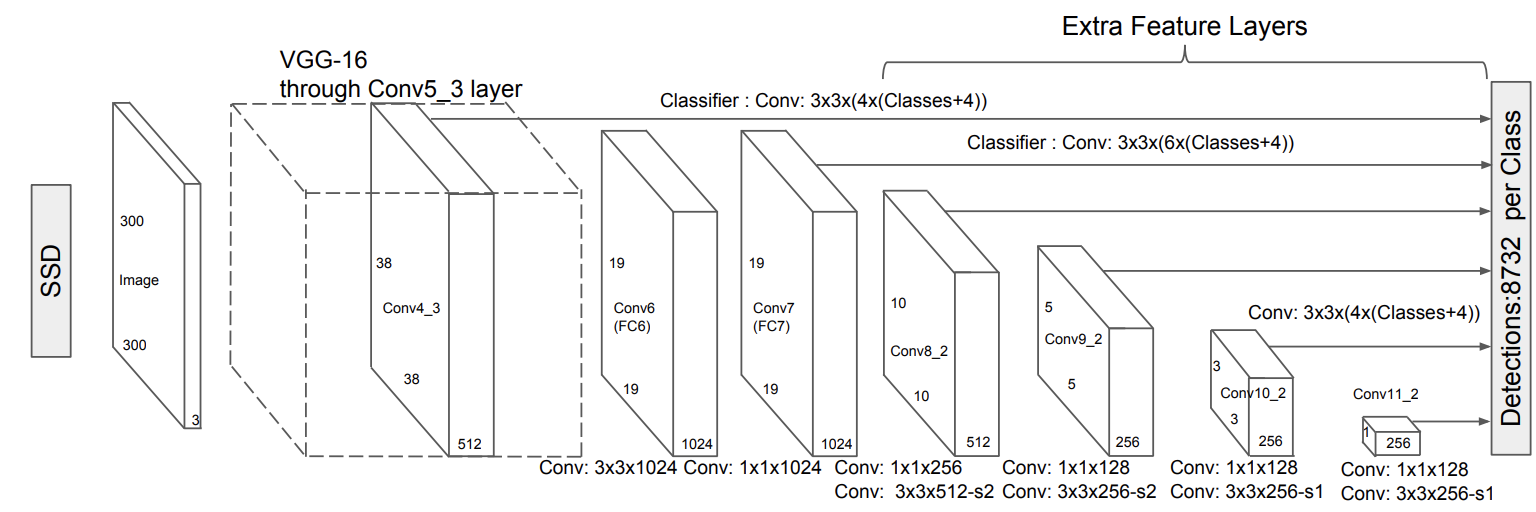
SSD processes an input image (typically 300×300) through the base network, usually a pre-trained convolutional neural network (e.g., VGG16) that extracts feature maps from the input image. It then appends a series of extra feature layers that progressively decrease in size. Each of these layers is used to make object predictions. SSD use Multi-scale Feature Map feature maps from different layers of the base network to make object prediction. It predict the offsets and class scores. These multi-scale feature maps help detect objects of different sizes.

SSD uses priors boxes (also known as anchor boxes), a set of predefined bounding boxes with different aspect ratios and scales. These prior boxes are selected based on an Intersection over Union (IoU) usually with a score greater than 0.5. That closely resemble ground-truth bounding boxes. Each feature map applies small convolutional filters to generate scores for object categories and bounding box offsets(offsets from these default boxes to the actual object bounding boxes), producing many predictions. The loss function for the SSD model is the weighted sum of the localization loss and the confidence loss. Finally, SSD applies Non-Maximum Suppression (NMS) to eliminate redundant boxes and output the final detections. The final detection offset is then decoded into real boxes coordinates.
The shape and number of anchor boxes generated depends on the underlying Convolution Neural Network architecture used for mapping.
Difference between YOLO and SSD
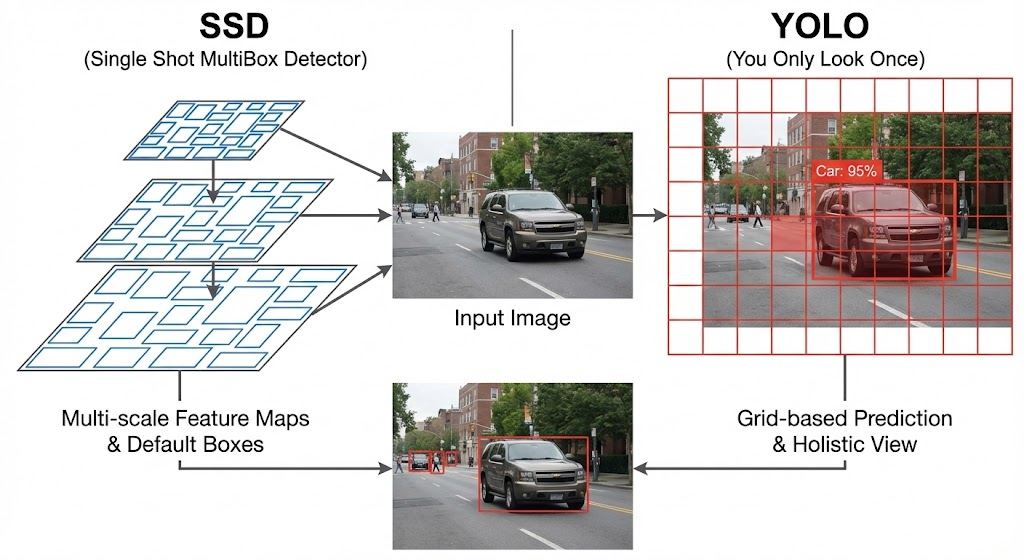
YOLO and SSD are both single-shot object detection models but they work differently
1. Small Objects
YOLO predicts objects using a single grid-based view of the image while SSD detects objects using multiple feature maps at different scales making it better for detecting small objects.
2. Default boxes generation
Another difference is on how the anchors are created. Since YOLO (v2, v3, etc.), it use uses dataset-driven anchor shapes obtained from the training dataset using k-means clustering on the ground-truth box widths and heights. This gives them the most dominant sizes of the bounding boxes from the dataset. These anchor shapes are then placed at every grid location. SSD instead use default achor boxes computed at different scales.
3. IOU difference
Both SSD and YOLO use IoU to determine which anchors correspond to which ground-truth boxes during training.
- SSD usually marks all anchors above an IoU threshold (e.g., 0.5) as positive matches.
- YOLO usually assigns each object to the best-matching anchor (or a small set of anchors in newer versions).
4. Accuracy and Object Detection Performance
YOLO generally outperforms SSD, especially in complex scenes (with very cluttered environments) or with smaller objects, allows it to capture fine-grained details more effectively. YOLO's architecture, which divides the image into a grid and predicts bounding boxes and class probabilities directly. It is better suited for applications that require high precision and the ability to detect many objects in a single image. YOLO gets comparatively more localization errors and has difficulty detecting close objects.
5. Speed and Real-Time Performance
YOLO becomes very fast and is ideal for situations where detection needs to happen instantly such as live video, obtaining higher fps. SSD work well for detecting objects of various sizes while staying fast enough for real-time use.
Comparison of frames processed per second (FPS) Source
YOLO reaches more than twice the mean Average Precision (mAP) compared to other real-time systems, which makes it a great candidate for real-time processing.
6. Low-power devices
SSD can use a lightweight backbone networks such as MobileNet which are optimized for low-compute environments. SSD is better if working with limited hardware resources and need a simpler and more efficient model, trading off some performance for small model size while still mantaining reliability. They achieve comparatively better performance in a limited resources use case. It has a very modest exactness trade-off. SSD recorded 59 FPS with mAP 74.3% on SSD300 and 22FPS with mAP 76.9% on SSD500. It makes SSD a common choice for embedded systems and mobile devices, with the combination of TensorFlow Lite conversion and quantization it is extremely fast to run.
Example
Model used
YOLO11 was released by Ultralytics on September 10, 2024, delivering excellent accuracy, speed, and efficiency. https://docs.ultralytics.com/models/yolo11#overview
Yolo26: Ultralytics YOLO26 is a unified family of real-time vision models described in the Ultralytics YOLO26 paper. It introduces native end-to-end inference, a lighter detection head, an updated training recipe, and task-specific heads for detection, segmentation, pose estimation, classification, and oriented detection https://docs.ultralytics.com/models/yolo26#overview YOLO26, released in January 2026 by Ultralytics, is an end-to-end, edge-optimized model supporting five core tasks: object detection, instance segmentation, pose estimation, oriented object detection (OBB), and image classification. It achieves the highest accuracy in the YOLO lineage while maintaining fast inference speeds.
SSD300 implemented in PyTorch with a VGG16 backbone. https://docs.pytorch.org/vision/main/models/generated/torchvision.models.detection.ssd300_vgg16.html
Benchmark
Barbell and Plate Detection
Using ultralytics library it is extremely convienient to train and run a model. The dataset used is from roboflow
from ultralytics import YOLO
# Download/load pretrained YOLO model
model = YOLO("yolo11s.pt")
# Train
results = model.train(
data="./barbell detection.v2i.yolov7pytorch/data.yaml",
epochs=10,
imgsz=640,
batch=16,
device=0,
workers=0,
project="runs",
name="barbell_detector",
pretrained=True,
patience=20,
save=True
)
# Evaluate on validation/test set
metrics = model.val()
print(metrics)while for the SSD i used the pytorch pretrained model ssd300_vgg16, ssd with input images of 300x300 using vgg16 backbone.
from torchvision.models.detection import ssd300_vgg16
from torchvision.models.detection.ssd import SSD300_VGG16_Weights
NUM_CLASSES = 3
# Barbell + plate + background
weights = SSD300_VGG16_Weights.DEFAULT
model = ssd300_vgg16(weights=weights)
# Replace classification head
in_channels = model.head.classification_head.module_list[0].in_channels
num_anchors = model.anchor_generator.num_anchors_per_location()
from torchvision.models.detection.ssd import SSDClassificationHead
in_channels = [512, 1024, 512, 256, 256, 256]
num_anchors = model.anchor_generator.num_anchors_per_location()
model.head.classification_head = SSDClassificationHead(
in_channels=in_channels,
num_anchors=num_anchors,
num_classes=NUM_CLASSES
)Try yourself the result on this test image:
Bar Path tracking
Comparing prediction on Video Object Detection
Comparison of object detection predictions generated by YOLO and SSD on the same video sequence. The examples highlight differences in object localization and detection behavior between the two models.
 YOLO
YOLO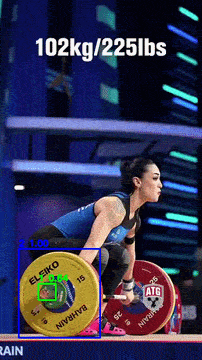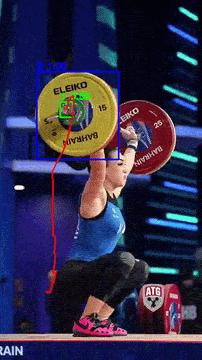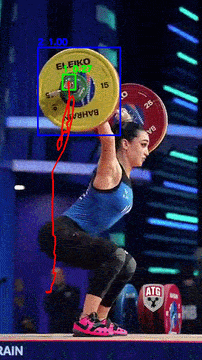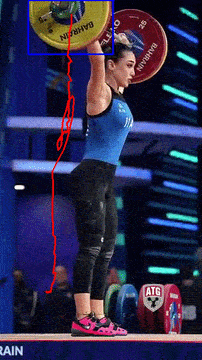 SSD
SSDConsiderations
- SSD uses default anchor boxes with a stricter spatial assignment strategy, causing box shapes to vary across locations. This can reduce localization stability.
- SSD prediction is better with the smaller barbell with 0.9 confidence vs 0.7 confidence for YOLO.
- YOLO runs at higher FPS with better real-time performance.It produces smoother trajectory estimates, as evidenced by the reduced number of spikes in the predicted bar path.